If you’ve ever wanted to treat set of links on a website as a web feed (so you can subscribe and be notified of updates), you might find our new feed creation tool useful.1
You can use the tool to create a feed from almost any publicly accessible webpage. That includes:
- Twitter streams
- Public Facebook timelines
- Search results on a website
Here are a few cases and examples where you might want to use Feed Creator:
- A webpage has no feed of its own
For example: Twitter accounts or public Facebook timelines2
- There is a feed, but not for the items that interest you
For example: Search results on a website or a category on a news site
How does it work?
Our service sits in between your feed reader (e.g. NewsBlur, Feedly, IFTTT) and the publisher’s website.
If a website already offers a feed for the information you’re interested in, this is typically how your feed reader gets updates after you subscribe to the feed:
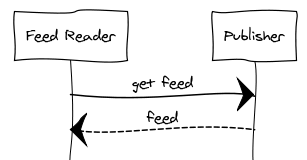
If there is no suitable feed, our service produces one based on the information you give it. You then subscribe to the feed we generate. Now when a feed reader requests the feed, here’s what happens behind the scenes:
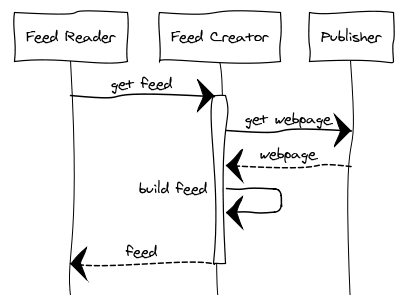
Getting started
To use the feed creator you will need:
- The URL of the source page which contains the items you’re interested in.
- Some knowledge of HTML (and CSS for advanced selection)
Before we go on, I’d like to stress that if there’s already a feed associated with the webpage, you should use it instead of relying on this tool.3 Feed Creator extracts links from the webpage by looking at its HTML.4 If a website gets redesigned, HTML changes could break our generated feeds.
Extracting links: 3 different ways
If you supply only the page URL, Feed Creator will return the first set of links it encounters in the HTML. This will include things like navigation elements – which usually appear at the top of the page. That’s probably not what you want. Below we’re going to look at 3 different ways to extract the items you’re interested in.
1. Selecting links using URL segments
The simplest way to narrow results to the set of links you are interested in is to see if you can find a URL segment that’s exclusive to that set of links.
Example
The official Noam Chomsky website has a page listing Chomsky’s articles. There is no RSS feed linked on the page nor in the HTML header.5 The first set of links point to other pages on the site (recent updates, books, audio and video) – these are navigation elements which we’re not interested in. Below those, the article links appear. These are the links we want to use in our RSS feed and monitor for updates.
If you hover your cursor over a few of the article links you’ll find that they all contain the segment ‘articles/’ – e.g. ‘articles/20130902.htm’, ‘articles/20130604.htm’. So it looks like ‘articles/’ is common to all these links. If you now hover over the navigation links, you’ll find: ‘books.htm’, ‘audionvideo.html’, ‘articles.htm’ (note, no forward slash here).
So, our brief examination suggests that the URL segment ‘articles/’ is exclusive to the article links we’re interested in. Let’s go ahead and try creating a feed from this information:
- Visit the Feed Creator site
- In the page URL field enter:
http://chomsky.info/articles.htm - In the ‘keep links if link URL contains’ field:
articles/ - Click ‘Preview’ and wait for results.
- If results look okay, you can subscribe to our generated feed using the button provided.
It’s important to note that what we’re trying to do is to identify patterns within the page that will not only return items that are currently on the page, but also pick up future entries. That’s why we don’t want to select links using identifiers that only apply to existing links (e.g. ‘20130902.htm’ or ‘20130604.htm’).
2. Selecting links using class and id attributes
Sometimes you’ll need more than a URL segment to select the links you want. If you know some HTML you can check the source of the page and see if there are class or id attributes associated with the links, their parent elements, or ascendants.6 If you find some, you can use those values to restrict your search to those elements.
Example
John Pilger’s website already offers an RSS feed for his articles, so this is one of those cases where you shouldn’t really use this tool. But I’ll use it as an example.
If you visit the articles page and click ‘Expand all articles’, you’ll see his latest articles at the top. If you examine the HTML, you’ll find the entries are marked up as follows:
<span class="entry">
<a href="[article url]" class="entry-link">[article title]</a>
<span class="entry-date" title="1 day ago">[article date]</span>
<a href="#" rel="nofollow" class="show-intro" id="showintro-815">Show intro...</a>
<span class="intro" id="article-intro-815">[article description]</span>
</span>
Each article entry is contained in a <span> element with the class attribute value “entry”. This element holds two link (<a>) elements. The actual article title and URL appear in the <a> element with class “entry-link”.
So let’s try creating a feed from this information:
- Visit the Feed Creator site
- In the page URL field enter:
http://johnpilger.com/articles - In the ‘look for links inside…’ field enter:
entry-link - Click ‘Preview’ and wait for results.
Here’s a direct link to results.
3. Selecting links using CSS selectors
For more advanced selection, you can use CSS selectors. Note that this selection method cannot be used in combination with the previous one, and we don’t yet offer form fields for entering selectors, so you’ll have to create the URL by hand. You can refer to the information in the request parameters table to see how these should be used.
Example
First, let’s see how the previous example looks like using a CSS selector:
- Page URL:
http://johnpilger.com/articles - item parameter:
.entry-linkora.entry-link
Here’s a direct link. It should produce the same results as in the previous example.
Now let’s look at a more complicated example: a Twitter timeline. If you view a Twitter timeline in your browser, this is how tweets are currently marked up in HTML:7
<div class="tweet original-tweet js-stream-tweet ...">
<span class="icon dogear"></span>
<div class="content">
<div class="stream-item-header">
<a class="account-group ..." href="..." data-user-id="...">
<img class="avatar js-action-profile-avatar" src="..." alt="">
<strong class="fullname js-action-profile-name ...">...</strong>
<span>‏</span>
<span class="username ..."><s>@</s><b>...</b></span>
</a>
<small class="time">
<a href="[tweet URL]" class="tweet-timestamp ..." title="[date]">
<span class="_timestamp js-short-timestamp ...">1h</span>
</a>
</small>
</div>
<p class="js-tweet-text tweet-text">[tweet text]</p>
...
</div>
</div>
Notice that the tweet URL appears in the element which holds the date, and there is no suitable title (unless you consider the tweet text to be the title) to use for feed items. So here we’re going to tell Feed Creator to omit item titles, and to use the tweet URL as the item URL. We could tell it to use the tweet text (p.tweet-text) as the description, but then we wouldn’t know who tweeted it (could be a retweet), so we’ll tell it to use the parent element (div.content). Here’s what our parameters will look like:
- Page URL:
twitter.com/fivefilters/(use any Twitter account you like) - item:
.original-tweet - item_url:
a.tweet-timestamp - item_desc:
.content - item_title:
0
If we stop here, we’ll find that the description will contain text from elements within div.content which we’re not interested in. So let’s remove these elements using the strip parameter: .stream-item-footer,.username,.js-short-timestamp
Here’s a direct link.
Hosted service with self hosting option
Our hosted service (the one accessible on createfeed.fivefilters.org) is free to use. It is intended for personal use and to show you what the feed creator application can do. We limit results to 10 items per feed and we’ll soon start caching webpages for around 30 minutes.
If our service turns out to be popular for subscribing to Twitter/Facebook feeds, there’s a possibility that these companies will block access. If you want to avoid that happening, you should consider running your own copy of the code. You’ll find information on the self-hosted package and a ‘buy’ button at the bottom of the Feed Creator page.
That’s all for now. Hope you found the guide useful. Feel free to comment or post a question on our help page if you like.
- We announced this service in May, but have since improved it and made it available for self-hosting. ↩︎
- Facebook and Twitter don’t like RSS. When you visit a public account on either site, you will not find RSS links on the page nor in the HTML header (which is how other services usually detect if there’s a feed associated with a page). Facebook can in fact produce a feed for public pages, but you’ll have to do some work to get the feed URL. Twitter no longer produces a feed, so you’ll have to use a service like ours. ↩︎
- If a site publishes a feed, they’re generally committed to maintaining it. People who subscribe to the feed depend on it to get notified of updates, so it’s not really in the publisher’s interest to remove the feed. ↩︎
- We don’t yet support pages which rely exclusively on Javascript to load content. ↩︎
- Chomsky.info used to link to one of my earlier projects which produced an RSS feed for their latest news page. They then moved to Blogger, which provides feeds. Now they appear to be using Facebook for their latest news. ↩︎
- The easiest way to find class and id attributes to use as selectors is to use Firefox’s page inspector. Simply right click a link or some other element on the page and select ‘Inspect Element’. ↩︎
- When viewing the HTML source of a webpage, or using the Firefox page inspector, you should bear in mind that it might not be seen the same way by our software. Servers may send back different responses depending on where the request originates, and what it contains. Another issue is how the HTML response is parsed. Even if the server sends back the same response to us as it does to your browser, your browser could parse it differently to our application (which uses PHP’s built-in HTML parser). ↩︎